1000ドルPC(MINISFORUM UM790 Pro)に生成AIをデスクトップで動かすソフトJanを導入した。今回はJanに用意されていない生成AIを追加導入する方法を紹介したい。
JanはGGUF形式に量子化 されたモデルを使用するので、追加できる生成AIは量子化 モデルが公開されていることが条件となる。今回追加したのはELYZA-japanese-Llama-2-7Bだ。
ELYZA-japanese-Llama-2-7B
モデルの追加方法
Janを起動し、生成AIのモデルをダウンロードする画面(Hub画面)を表示すると、「
Hub画面
ここをクリックすると下記のサイトが表示され、手順が説明されているので基本的にこの通りに行えばよい。
jan.ai
そうは言っても初めての方は戸惑うであろうし、この手順ではうまくいかない可能性が高いと思う。私が今回掴んだコツというか、着実に行う手順があるのでをここにメモしておきたい。
マニュアルでは以下の手順となっている。
~/jan/models フォルダーに移動する
<modelname> という名前のフォルダーを作成する (例: tinyllama)
フォルダー内に次の構成を含む model.json ファイルを作成する
id プロパティが作成したフォルダー名と一致していることを確認する
url プロパティが .gguf で終わる直接バイナリ ダウンロード リンクであることを確認する。これで、絶対ファイルパスを使用できるようになる
engineプロパティがnitroに設定されていることを確認する
私がお勧めする方法は以下である。
~/jan/models フォルダーに移動する
すでにあるフォルダー(例:trinity-v1.2-7b)をコピーして新しいフォルダを作る(例:trinity-v1.2-7b2)
trinity-v1.2-7b2にあるmodel.json ファイル内のidを作成したフォルダ名に合わせる
JanのViewメニューにあるReloadを選択し画面をリロードして作成したフォルダ名のモデルがHub画面に表示されることを確認する
model.json ファイル内の別のパラメタを一箇所修正し、再度画面をリロードしてモデルがHub画面に表示されていることを確認する
上記の4と5を繰り返しながら修正していく方法である。例えばtrinity-v1.2-7b2ではモデルの画像は以下のパラメタとなっている。
"cover": "https://raw.githubusercontent.com/janhq/jan/dev/models/trinity-v1.2-7b/cover.png"
これをELYZAの画像にするには以下のようにURLを変更する。
"cover": "https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct/resolve/main/key_visual.png"
画像が正しく表示されたら、次はファイル名を変更するといった具合である。最終的にELYZA-japanese-Llama-2-7B用にmodel.json は以下のようになった。
{
"sources": [
{
"filename": "ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.gguf",
"url": "https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/blob/main/ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.gguf"
}
],
"id": "elyza-japanese-llama-2-7b",
"object": "model",
"name": "ELYZA japanese Llama 2 7b",
"version": "1.0",
"description": "ELYZA is an experimental model merge using the Slerp method. Recommended for daily assistance purposes.",
"format": "gguf",
"settings": {
"ctx_len": 4096,
"prompt_template": "[INST] {prompt} [/INST]",
"llama_model_path": "ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.gguf"
},
"parameters": {
"temperature": 0.7,
"top_p": 0.95,
"stream": true,
"max_tokens": 4096,
"frequency_penalty": 0,
"presence_penalty": 0
},
"metadata": {
"author": "Jan",
"tags": ["7B", "Merged", "Featured"],
"size": 7274877600,
"cover": "https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct/resolve/main/key_visual.png"
},
"engine": "nitro"
}
"prompt_template"という項目はどう直せばよいのか迷うと思うが、これはELYZAのHuggingfaceのページにある使い方(Python のサンプルコード)から推測するしかない。
これでうまくいけばDownloadボタンが押せるようになるはずだ。ちなみに私はダウンロードが直ぐに終了し、正しくダウンロードできなかったのだが、以前にダウンロードしたファイルをフォルダにコピーし、無事Useボタンは押せる状態になった。動けばOKなのだ(笑)。
ダウンロードするのはHuggingfaceのmonongaさんのページだ。
huggingface.co
いつも使わせてもらってます。ありがとうございます。
実行結果
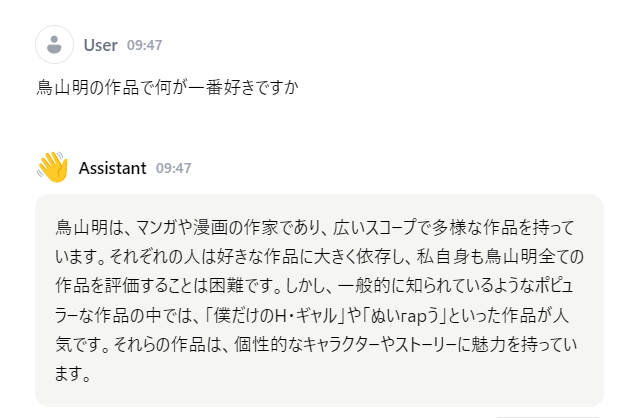
好きな鳥山明 の作品 by ELYZA
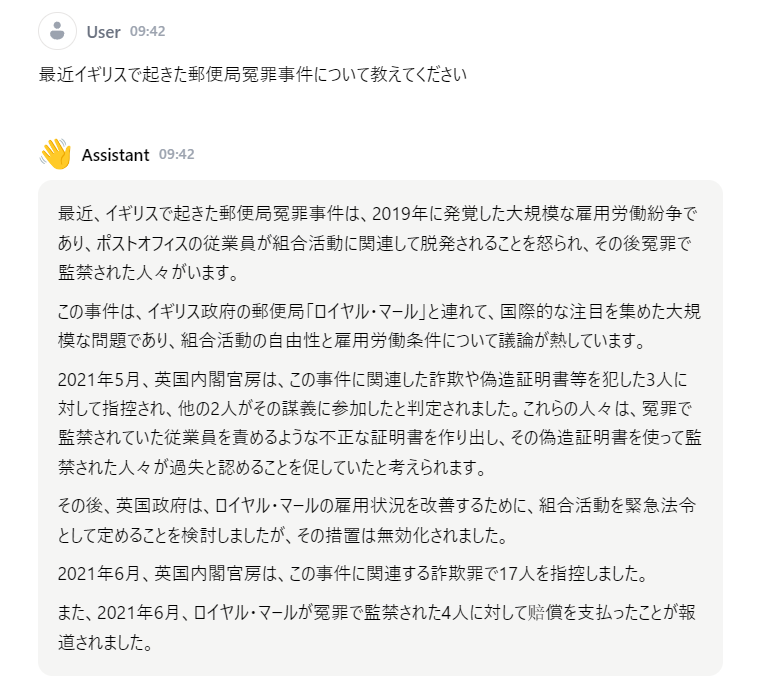
日本語で学習しただけのことはあるようだ。当たり障りのない回答ではあるが、他の生成AIもこれくらいの回答は返して欲しい。
次は専門的テーマについて専門家の意見を参考にするためのプロンプトを試してみた。私が以前からAIの最新情報を学ぶために参考にしているIT naviさんのページにあった方法である。
note.com
ディベート の結果 by ELYZA
全くディベート になっていないぞ! これは期待外れだ。。
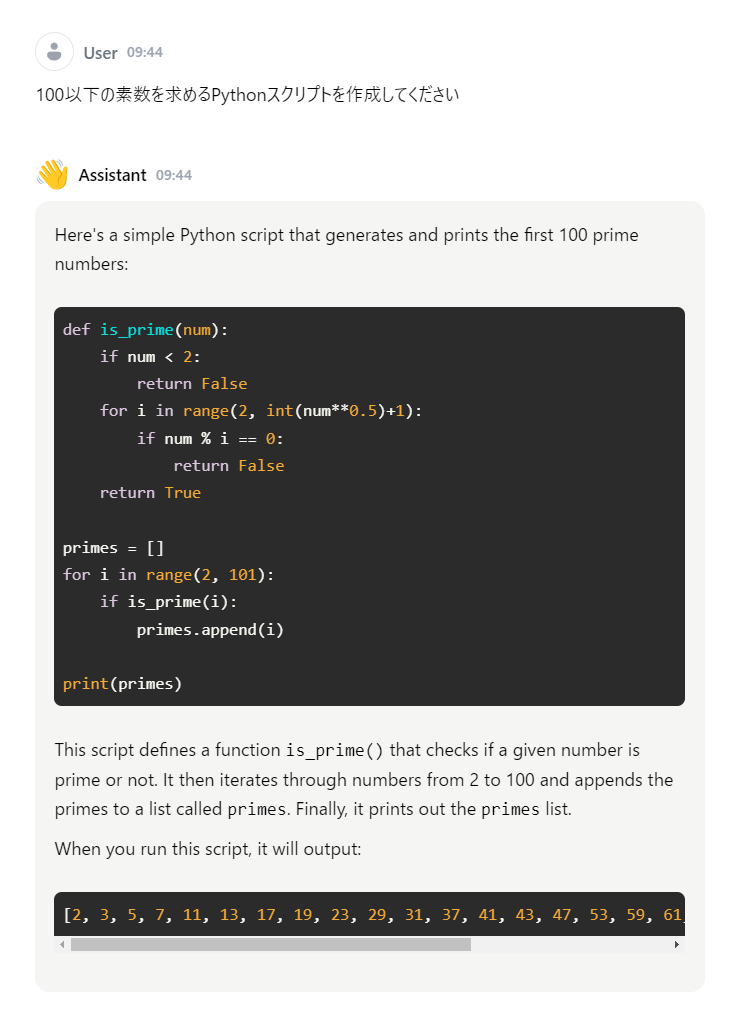
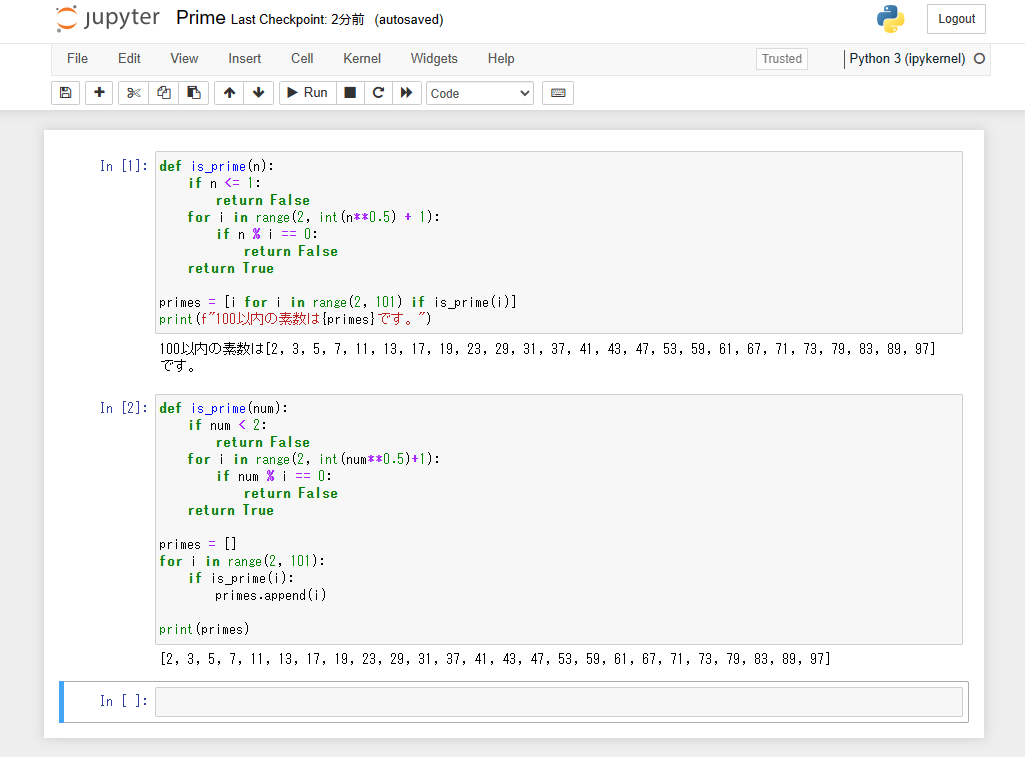
最後は例によって100以下の素数 を作成するPython スクリプト を頼んでみた。
Python スクリプト by ELYZA
最初の関数 is_prime は正しく動くが、関数 find_prime はエラーになった。最初の関数だけでやめておけばいいのに。find_prime は何をしているのか私には理解できない。
Python スクリプト の実行結果
まとめ
使ってみたい生成AIをJanに追加して動かすことができた。上記で紹介したmonongaさんのページではサイバーエージェント が開発した cyberagent -calm2-7b、LINEが開発した line-corp-japanese-large-lm-3.6b-instruction-sft 、最近話題のGoogle が開発した 量子化 モデルが公開されている。どのモデルも個性がありそうだ。是非試してみたいと思っている。


")




















 USB 2.0 USB PD対応 MacBook Pro/Air iPad Pro/Air 4 Galaxy S21 Pixel LG 対応")