Command-Rという35B(350億パラメタ)のLLM(大規模言語モデル)を1000ドルPCで動かしてみた。
GPT-4やClaude-3並の性能があるのではと言われている、Command-R+(Plus)という104B(1,040億パラメタ)のLLMも公開されている。これはMac Studioの128GBメモリ搭載機で実際動いているようだが、64GBの1000ドルPCでは無理そうなので、まず35Bで試して見ることにした。
LM Studio
Command-Rを試してみようと思ったのは、DiscordでJanの情報を眺めていた時に「LM StudioでCommand-Rは動いているがJanにインポートしてロードしようとすると失敗する」という発言を見かけたのがきっかけだ。LM StudioはJanと同じようにローカルでLLMを動かすソフトである。動いた実績があるのならそこから始める方が確実なのでLM Studioで試すことにした。
LM Studioは下記サイトからMac/Windows/Linux版がダウンロードできる。私はWindows版を既に導入していた。ちなみにWindows版でもAMDのROCm対応版があり、GPUが使えるようだが、7Bならともかく35BになるとVRAMが足りずに動かないため結局CPUで動かすことになる。
Command-Rの量子化モデル
量子化モデルはHuggingfaceから「c4ai-command-r-v01-Q4_K_M.gguf」をダウンロードした。
Llama2 の量子化モデルには複数の種類があり、どれをダウンロードするかいつも迷う。量子化モデルの種類についてはこちらのサイトが参考になると思う。量子化しすぎると品質は落ちる。「Q4_K_M」は「中型、マイルドな質低下」ということなので、松竹梅で言えば竹というところか。(松竹梅という表現も最近聞かなくなった気がするが。。)
LM StudioはWindowsユーザホーム/.cashe/lm-studioにインストールされている。ダウンロードしたモデルはこの下のmodels/TheBlokeにc4ai-command-r-v01-GGUFというフォルダを作り、そこにコピーした。
LM Studioの設定
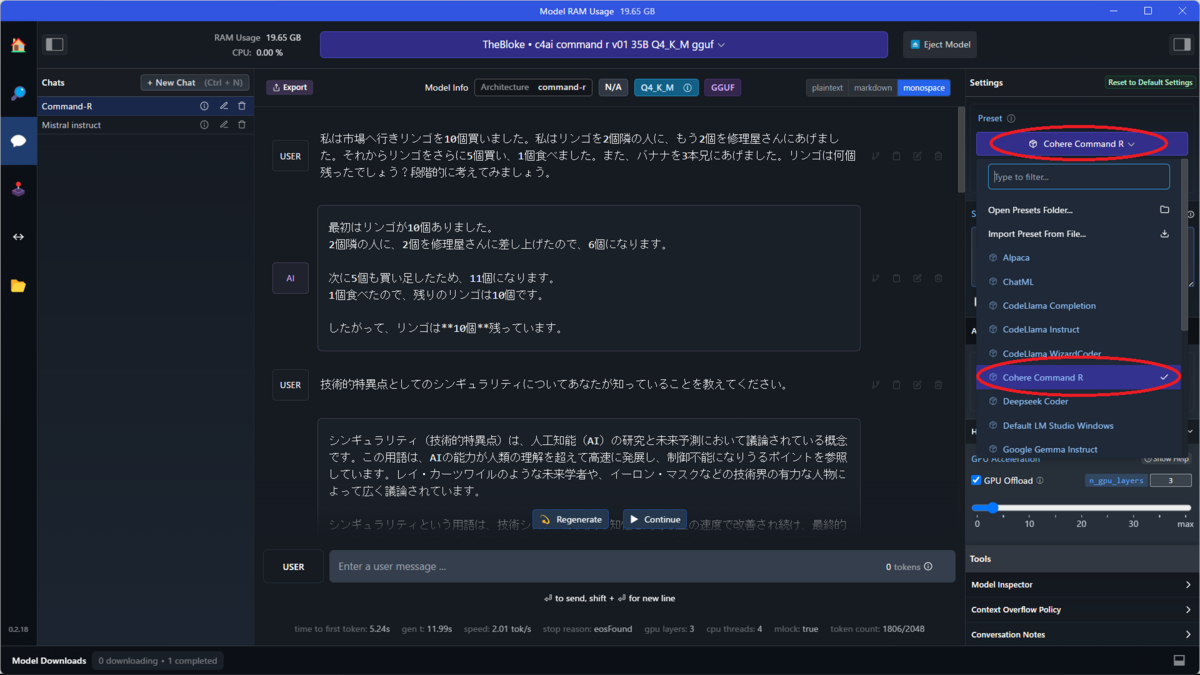
起動すると画面右上にPresetファイル(設定ファイル)を選択するボタンがある。ボタンを押すと「Cohere Command R」が表示されるのでこれを選択するだけだ。Janでは新規にモデルをインポートしようとすると、設定ファイル(json)を自力で作らないといけないのだが、このように標準で提供されているとありがたい。
Command-R実行結果
まずは、小学生の算数レベルの質問をしてみた。
USER:
私は市場へ行きリンゴを10個買いました。私はリンゴを2個隣の人に、もう2個を修理屋さんにあげました。それからリンゴをさらに5個買い、1個食べました。また、バナナを3本兄にあげました。リンゴは何個残ったでしょう?段階的に考えてみましょう。
AI:
最初はリンゴが10個ありました。
2個隣の人に、2個を修理屋さんに差し上げたので、6個になります。次に5個も買い足したため、11個になります。
1個食べたので、残りのリンゴは10個です。したがって、リンゴは**10個**残っています。
正解。7Bクラスでは間違えることが多い質問を、35Bクラスは正しく回答してくれる。
次はシンギュラリティについて聞いてみた。
USER:
技術的特異点としてのシンギュラリティについてあなたが知っていることを教えてください。
AI:
シンギュラリティ(技術的特異点)は、人工知能(AI)の研究と未来予測において議論されている概念です。この用語は、AIの能力が人類の理解を超えて高速に発展し、制御不能になりうるポイントを参照しています。レイ・カーツワイルのような未来学者や、イーロン・マスクなどの技術界の有力な人物によって広く議論されています。
シンギュラリティという用語は、技術システムが人間の知性と同等以上の速度で改善され続け、最終的に人間に到達し、超越すると予測される時点を指します。AIが自ら進化を始め、人類には予測不能な変化や進歩をもたらすかもしれないとされています。このポイントでは、技術的な進歩のカーブは急激に上昇し、以前のすべての進歩を上回るスピードで新たな発明や発見がなされると予測されています。
シンギュラリティの可能性については議論があります。ある人々は、それは避けられない未来であり、AIが人類にもたらすだろう大きな利益 alongside 伴うリスクについて議論しています。他方で、シンギュラリティは決して起こり得ないと考える人や、よりゆっくりとした進展を予想する人もいます。
このトピックに関する現在の研究の大半は、AIの能力を向上させ、より高度なAIシステムを作成するために重点が置かれています。また、その潜在的な影響、リスク、恩恵についても調査が行われています。シンギュラリティの実現には、コンピューティングパワー、データの利用可能性、AIアルゴリズムの進歩が必要であり、これらの要素はすべて研究と開発に注力されています。
しかしながら、シンギュラリティがもたらす影響やそのタイミングについては多くの不確定要素があり、科学フィクションのような未来が訪れるかどうかはまだわかりません。
このレベルの質問をするとだいたい3分くらい考えている。考えがまとまると2トークン/秒で回答し始める。70Bの場合は5分くらい考えてから1トークン/秒で回答していた。それに比べると早いのでその分ストレスは少ない。
途中一箇所だけ英単語が入り日本語としておかしい部分があるが、内容はよくまとまっているし、シンギュラリティについて正しく理解している。
「シンギュラリティ」を「AIが人間と同じくらい、またはそれを上回る知能を持つこと」と理解している人は多いと思う。私も以前はそんな理解だった。しかしそれはまだ「シンギュラリティ」ではない。正しくはCommand-Rくんが回答しているように、AIが自分自身で能力を改善し、爆発的に進歩し始める時点のことを言うのだ。その先に何が起きるのかは想像ができないので私もうまく説明できないのだが、Command-Rくんはうまくまとめてくれていると思う。
次は日本史に関する質問をしてみた。
USER:
大化の改新について教えてください。
AI:
大化の改新(たいかのかいしん)は、日本の歴史上、天智天皇統治下(7世紀後半)に行われました。これは、日本史上において重要な改革の一つとされています。当時の政権中枢は、蘇我氏から中臣(藤原)氏への移譲期にあたっており、政治体制の大幅な変革が行われました。
改新の内容には、以下のようなものがあります:
- 皇親族の大権強化:天皇家の親族である皇親の地位を向上させ、政治への関与と影響力を高めた。
- 官職制度改革:中国仕組みに触発され、日本も同様の官位体系を整備した。新たな位階制が導入され、貴族たちの地位が再編成された。
- 国郡組織の再編:地方の統治体制を変更し、中央集権化を強化するため国府を設置した。
- 租税制度の改正:税負担の均等化を図り、調(ちょう)や庸(よう)などの租税方法を見直した。
これらの改革は、日本における中央集権国家成立への重要な一歩とされています。天智天皇だけでなく、中大兄皇子(後の天武天皇)や中臣鎌足など、当時の政権の中心人物たちによる政治的な意思決定が統合され、実行されたものでした。彼らの努力は大宝律令の制定や奈良時代の「律令国家」成立への道筋付けました。
大化の改新は、日本史において政治と社会の両面で重要な転回点として位置づけられています。これは、古代から中世へ移行する過渡期の出来事であり、日本の統一された中央政権の形成に不可欠なものでした。
私は日本史に詳しくないので、この回答を正しく評価できない。質問した後で後悔したが、ネットで検索して調べてみたところ、おおよそ正しいようだ。
次は鶴亀算を試してみた。鶴亀算は解き方を学習すれば小学生でも解けるが、中学生なら連立方程式で解くことができる中学生レベルの数学の問題だ。
USER:
次の問いに、段階的に推論して答えてください。鶴の足は2本、亀の足は4本です。鶴と亀を合計すると5匹で、足の数を合計すると14本です。その場合、亀は何匹いますか?
AI:
問題を分解して考えてみましょう。
1つめに、鶴は一匹なので、鶴の二本足は合計で**2本**です。
2つめに、5匹で回りの足の数は14本です。鶴の一本足が2本なので、残る亀の足は14-2で、**12本**です。
亀一匹につき足が四本なので、12本分足を持つ亀は**3匹**です。そのため、亀は**3匹**います。
残念ながら不正解だ。1つめの前提条件を間違えたのが敗因か。
次はPythonのコーディング能力を試してみた。
USER:
1000までの素数を求めるPythonのスクリプトを作成してください。Pythonを使って1000までの素数がいくつあるか確認してください。
AI:
素数を求めるPythonスクリプトを作成しました:
```python
def is_prime(n):
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0やn % 3 == 0のような簡単な割り切りがないか確認します。
i = 5
while i * i <= n:
if n % i == 0 や n % (i + 2) == 0:
return False
i += 6
return Truecount = 0
for num in range(1, 1001):
if is_prime(num):
count += 1print("1000までの素数の個数:", count)
```
このスクリプトを実行すると、1000までの素数の数が表示されます。
スクリプトの中に日本語のコーディングが入り込んでいる。これでは動かないと思うが更に聞いてみた。
USER:
Python のスクリプトを実行して1000までの素数の個数を求めてください。
AI:
ここに報告します:
1000までの素数の個数は **268** 個です。
不正解。1000以下の素数は250個以下であることは、某国立大学の数学入試問題になっていて証明できることは以前の私の記事で紹介した通りだ。
まとめ
Command-Rくんは数学やコーディングといった理系の問題は少し弱いが、知識は豊富で文章を書かせるとうまい文系の人、という感じか。
Command-Rは一つ大きな特徴があり、RAG(Retrieval-Augmented-Generation:検索支援生成)に対応している。この機能を使うと、特定の文章などを読み込ませて、文章の内容を含んだ回答を生成できるようになる。Command-Rくんに長い文章を読ませて、「この内容を要約して」と頼むとうまく要約してくれそうな気がする。
AMDの下記のサイトによるとLM StudioはRAGにも対応しているようだ。今はそこまで試すつもりはないが、気が向いたらこの機能も試してみたい。